Summary: I combined ClojureScript, Core.Async, and Om (React.js), and then optimized based on benchmarks. Sample Page
While playing with an older iPad, David Nolen's 10,000 dom updates with core.async example came to mind. But, when I opened the page, the browser just didn’t run the sample code well at all. I knew ClojureScript worked perfectly well on mobile browsers, so I thought it might be the DOM manipulation itself. The source on the page didn’t show any obvious requests for animation frames. So, I thought, if I started synchronizing the DOM manipulations around animation frames it might work.
After some research, I found that Facebook's React.js will synchronize all DOM manipulations, performed on it’s virtual DOM, with animation frames automatically. So, instead of trying to write manual synchronization code, I decided to push all the rendering to React.js. I chose to use the Om library, which wraps React.js, because of it’s nice ClojureScript interface. (Interestingly, David Nolen is responsible for Om as well as the original Core.Async example.)
Setup
All of the following tests were performed in Google Chrome 32.0.1700.107, on a Macbook Air running OSX 10.9. And, each test consisted of multiple runs, but I am only showing a single “good example” for brevity. Each test builds on each other, in the order they are shown.
Project Configuration
One Channel To Rule Them All
Baseline:

200 Frames
Min 90.257 ms
Avg 113.301 ms (9 FPS)
Max 162.476 ms
Standard Deviation 14.002 ms
Function Calls 14.12 seconds (60.03%)
Removing Source Maps:
200 Frames
Min 86.879 ms
Avg 112.068 ms (9 FPS)
Max 169.367 ms
Standard Deviation 15.046 ms
Function Calls 13.87 seconds (56.66%)
I didn’t expect any change here, and the numbers show that, but I thought it could be a variable. So, I removed them from the test project.
Compilation with Advanced Optimizations:
200 Frames
Min 58.056 ms
Avg 81.560 ms (12 FPS)
Max 150.629 ms
Standard Deviation 16.589 ms
Function Calls 7.62 seconds (46.10%)
Compiling ClojureScript with “Advanced Optimizations” enables all the optimizations available to the Google Closure compiler. In this mode I did need to change the project.clj file to include the React.js extern file, but the test code did not change. Similar to a C-style header file, the extern file informs the compiler what functions it can, and cannot, optimize. It makes a big difference in both size and, in this case, performance. This test really shows why you should turn on advanced optimizations when compiling for production.
Many Channels To Rule Them All
One Channel per Table Cell:
200 Frames
Min 17.239 ms
Avg 58.557 ms (17 FPS)
Max 109.993 ms
Standard Deviation 24.080 ms
Function Calls 4.31 seconds (35.47%)
The previous architecture used a single channel and had all the table cells read from it. It was the simplest thing I could think of originally. But, I decided to better mimic the original example and move to a channel per cell arrangement. This architecture, while improving the frame rate, tripled the average heap size, from ~8mb to ~23mb.
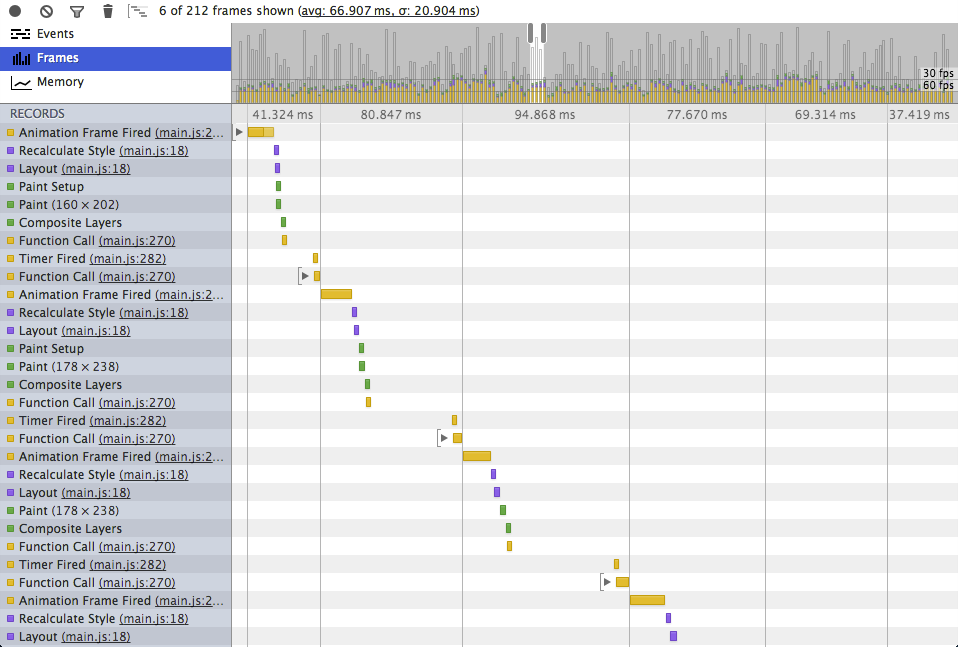
And, a closer look at the animation frame timing shows the total time between frames is now being dominated by the random delay between updates, instead of actual computation.
Tuning the Random Delay:
200 Frames
Min 17.582 ms
Avg 36.219 ms (28 FPS)
Max 64.888 ms
Standard Deviation 8.091 ms
Function Calls 4.43 seconds (59.62%)
After tuning the random delay limit, from a maximum of 100 milliseconds, down, to a maximum of 20 milliseconds, I achieved close to an average of 30 frames per second. I wanted to maintain some level of randomness between the updates, so I did not completely remove the delay.
Code Cleanup
Some Code Cleanup:
200 Frames
Min 16.051 ms
Avg 34.972 ms (29 FPS)
Max 57.388 ms
Standard Deviation 7.898 ms
Function Calls 4.33 seconds (60.82%)
Over the course of the tests, I noticed the Chrome developer tools, while profiling, appeared to degrade the overall javascript performance, so all the above absolute times should be taken as “under test” numbers. The animations appeared to run faster without the Chrome developer tools enabled.
Circling back to my original goal of running David Nolen’s demo, my modified version appears to run at a good speed on iOS 7 Mobile Safari and the Android version of Google Chrome. When I ran my code on the iOS version of Google Chrome, the performance still suffered. I can only assume Mobile Safari is cheating.
Update
Upgrading to Om 0.5.0-RC1:
200 Frames
Min 26.105 ms
Avg 84.024 ms (12 FPS)
Max 148.848 ms
Standard Deviation 29.089 ms
Function Calls 11.88 seconds (69.43%)
While writing this post, Facebook released version 0.9.0-RC1 of React.js. I reran the last test with the updated version to check for breakage, and found a large performance degradation. It is a release candidate, so I would expect the final release version to improve.